Solr配置详解
1. 目录结构说明
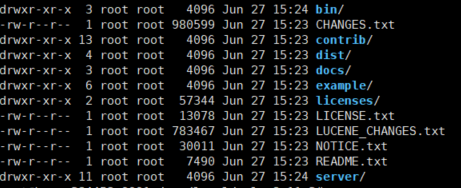
bin: Solr控制台管理工具存在该目录下。如:solr 等。
contrib: 该文件包含大量关于Solr的扩展。
dist: 在这里能找到Solr的核心JAR包和扩展JAR包。当我们试图把Solr嵌入到某个应用程序的时候会用 到核心JAR包。
docs: 该文件夹里面存放的是Solr文档,离线的静态HTML文件,还有API的描述。
example: 包含Solr的简单示例。
licenses: 各种许可和协议。
server: solr应用程序的核心,SolrCore核心必要文件都存放在这里。
#contrib
analysis-extras: 该目录下面包含一些相互依赖的文本分析组件 分词器相关。
clustering: 该目录下有一个用于集群检索结果的引擎。
dataimporthandler: DIH是Solr中一个重要的组件,该组件可以从数据库或者其他数据源导入数据到 Solr中。 dataimporthandler-extras: 这里面包含了对DIH的扩展。
extraction: 集成Apache Tika,用于从普通格式文件中提取文本。
langid: 该组件使得Solr拥有在建索引之前识别和检测文档语言的能力。
prometheus-exporter: 采集监控数据并通过prometheus监控 solr监控相关。 velocity:包含一个基于Velocity: 模板语言简单检索UI框架。
#server
contexts: 启动Solr的Jetty的上下文配置。
etc: Jetty服务器配置文件,在这里可以把默认的8983端口改成其他的。
lib: Jetty服务器程序对应的可执行JAR包和响应的依赖包。
logs: 默认情况下,日志将被输出到这个文件夹。
modules: http\https\server\ssl等配置模块。
resources: 存放着Log4j的配置文件。这里可以改变输出日志的级别和位置等设置。
scripts: Solr运行的必要脚本。
solr: 运行Solr的配置文件都保存在这里。solr.xml文件,zoo.cfg文件,使用SolrCloud的时候有 用。子文件 夹configsets存放着Solr的示例配置文件。每创建一个核心Core都会在server目录下生 成相应的core 名称 目录。 solr-webapp:Solr的平台管理界面的站点就存放在这里。
tmp: 存放临时文件。
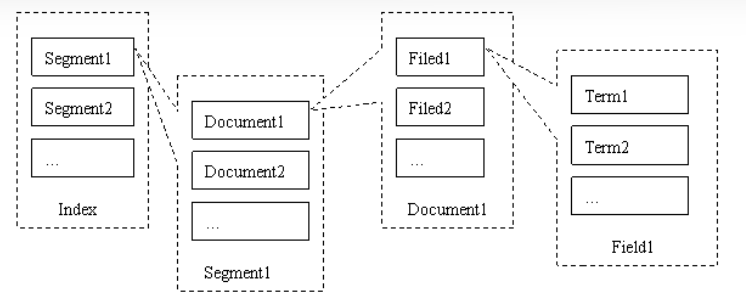
2. SolrCore结构
SolrCore内核:是运行在Solr服务器中的具体唯一命名的、可管理和可配置的索引,即内核就是Lucene中说到的索引。一台solr服务器可以托管一个或多个内核